AWS Lambda + Puppeteerでダイナミックレンダリングする
基本的には下記のサイトが非常に参考になった。 SSR をやめる。OGP 対応は Lambda@Edge でダイナミックレンダリングする。
この記事では Puppeteer は使っていないが、Puppeteer で目的のダイナミックレンダリングが出来そうだったのでやってみた。
基本的に上記のやり方を参考に進めて、キモであるダイナミックレンダリングするところだけ、Puppeteer を使うように変更した。今回は主にその部分の備忘録。Serverless も Webpack も使っていない。
全体の流れ
まずはざっくりとした全体の流れから。
- html, css, js とかのアセットを S3 に配置して静的ホスティングする
- その S3 を CloudFront 経由で配信する
- Lambda の Viewer Request で UserAgent からボットの判別をして、ボットだったらカスタムヘッダーを付与する
- Lambda の Origin Request でボット用のカスタムヘッダーが付いてたら Puppeteer でダイナミックレンダリングする
Viewer Request や Origin Request などの Lambda@Edge のライフサイクルイベントについては、公式がわかりやすい。
以下、CloudFront で配信するのが終わったあとのところから。
Lambda の Viewer Request で UserAgent からボットの判別をして、ボットだったらカスタムヘッダーを付与する
ほとんど参考記事のままだが、下記のような Viewer Request Function を準備して、Lambda 上のエディタにペーストしてデプロイ。 やっているのは、UserAgent がクローラーで、かつ html へのリクエストだったらダイナミックレンダリング用のカスタムヘッダーをつける、という感じ。
"use strict";
exports.handler = (event, context, callback) => {
const request = event.Records[0].cf.request;
const headers = request.headers;
const crawlers = [
"Googlebot",
"facebookexternalhit",
"Twitterbot",
"bingbot",
"msnbot",
];
const excludeExtentions = [
"jpg",
"png",
"gif",
"jpeg",
"svg",
"css",
"js",
"json",
"txt",
"ico",
"map",
];
const dynamicRenderHeaderName = "X-Need-Dynamic-Render";
const extention =
request.uri === null || request.uri === "/"
? ""
: request.uri.split(".").pop().toLowerCase();
const maybeHtml = !excludeExtentions.some((e) => e === extention);
const isCrawler = crawlers.some((c) => {
return headers["user-agent"][0].value.includes(c);
});
// UserAgentがクローラーで、かつhtmlへのリクエストだったらカスタムヘッダーをつける
if (isCrawler && maybeHtml) {
request.headers[dynamicRenderHeaderName.toLowerCase()] = [
{
key: dynamicRenderHeaderName,
value: "true",
},
];
}
callback(null, request);
};
Lambda の Origin Request でボット用のカスタムヘッダーが付いてたら Puppeteer でダイナミックレンダリングする
ここの流れとしては、
- npm init して package.json を生成
- Puppeteer とか必要なモジュールを npm install
- Puppeteer を使ってダイナミックレンダリングの処理を書く
- 実装が終わったら、node_modules とかも含めて zip 圧縮して Lambda 上から zip でアップロードして、デプロイする
という感じ。
Serverless を使うと zip 化してデプロイの作業が効率化出来るので実案件とかだと使った方が良さそうか。
ローカルの作業場所はどこでも良いので、おもむろに npm init -y とかで package.json を生成する。
そして必要なモジュールをnpm installしていく
"dependencies": {
"@serverless-chrome/lambda": "^1.0.0-55",
"chrome-remote-interface": "^0.27.0",
"puppeteer-core": "^1.11.0"
}
puppeteer-coreじゃなくてpuppeteerを普通にnpm installすると、Chromium も一緒にダウンロードしてしまって、そうなると Lambda の 50MB の制限に容易に引っかかってしまう。
なので Puppeteer1.7 以降から追加された、puppeteer-coreをインストールするようにする。
インストール出来たら実際に Puppeteer を使ってダイナミックレンダリングの実装をindex.jsに書いていく。
"use strict";
const launchChrome = require("@serverless-chrome/lambda");
const CDP = require("chrome-remote-interface");
const puppeteer = require("puppeteer-core");
exports.handler = async (event, context, callback) => {
const dynamicRenderHeaderName = "X-Need-Dynamic-Render";
const request = event.Records[0].cf.request;
const headers = request.headers;
// クローラーじゃなかったら何もしない
if (!headers[dynamicRenderHeaderName.toLowerCase()])
return callback(null, request);
// クローラーだったら、ダイナミックレンダリングする
let slsChrome = null;
let browser = null;
let page = null;
try {
// Chromeの立ち上げ
slsChrome = await launchChrome();
// WebSocketを使ってPuppeteerと繋げる
browser = await puppeteer.connect({
browserWSEndpoint: (await CDP.Version()).webSocketDebuggerUrl,
});
page = await browser.newPage();
await page.goto("https://ダイナミックレンダリングしたいURL/", {
waitUntil: "networkidle0",
});
const html = await page.content();
await browser.close();
await slsChrome.kill();
const response = {
status: "200",
statusDescription: "OK",
headers: {
"cache-control": [
{
key: "Cache-Control",
value: "max-age=100",
},
],
"content-type": [
{
key: "Content-Type",
value: "text/html",
},
],
"content-encoding": [
{
key: "Content-Encoding",
value: "UTF-8",
},
],
},
body: html.replace("<html", '<html style="background: #ff0;"'), // 試しにボットの時だけ背景色を黄色に変えてみる
};
return callback(null, response);
} catch (err) {
return callback(err);
}
};
こんな感じに。
ボットの時に元のコンテンツに変化がないと、ちゃんとダイナミックレンダリングされてるか分からないので、<html style="background: #ff0;">を入れて全体が黄色になれば OK という感じにした。
これが出来たらnode_modulesやpackage.json、index.jsなど含めて zip 化する。
その zip を Lambda にアップロードしてデプロイする。
注意点
Finder の右クリックで zip 化してしまうと Lambda で動かした時にエラーが出てしまう
zip 化はコマンドで行うと問題なかった。
package.json のある場所で、zip -r app.zip * とかで zip にする。
Origin Request の設定
Origin Request のデフォルトの設定だと、WebSocket で Puppeteer と connect するところでタイムアウトエラーになってしまった。
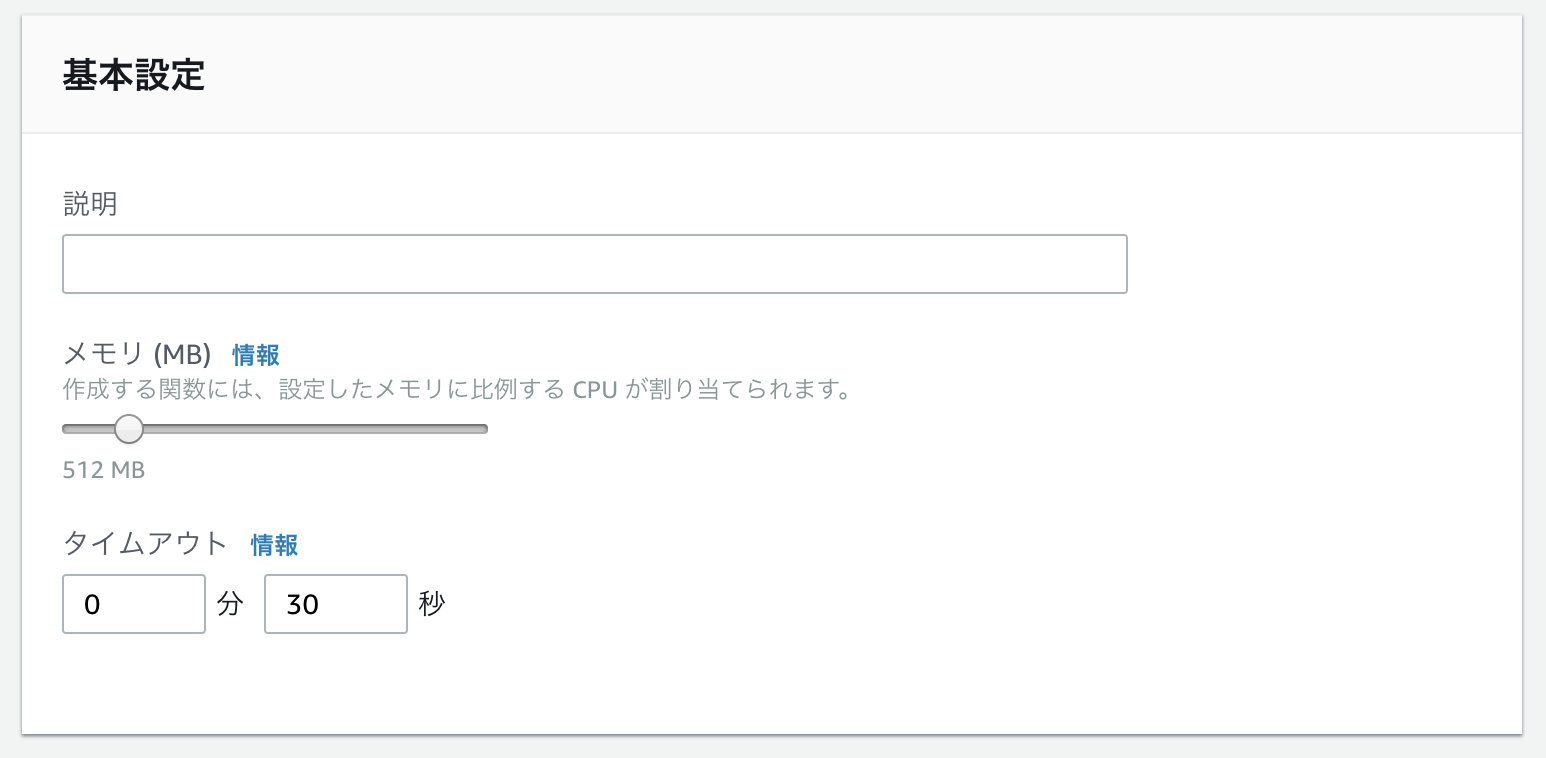
色々試したところ、どうも Lambda の管理画面上で設定できる、メモリとタイムアウトまでの時間を変更する必要があった。 デフォルトのマシンの性能だと非力すぎて、タイムアウトまでに処理が出来ない、ということのようだ。
デフォルトの設定から メモリ 128MB → 512MB タイムアウト 3 秒 → 30 秒 に変えたところエラーが消えて、無事に Puppeteer が Lambda 上で動いた。
動作確認
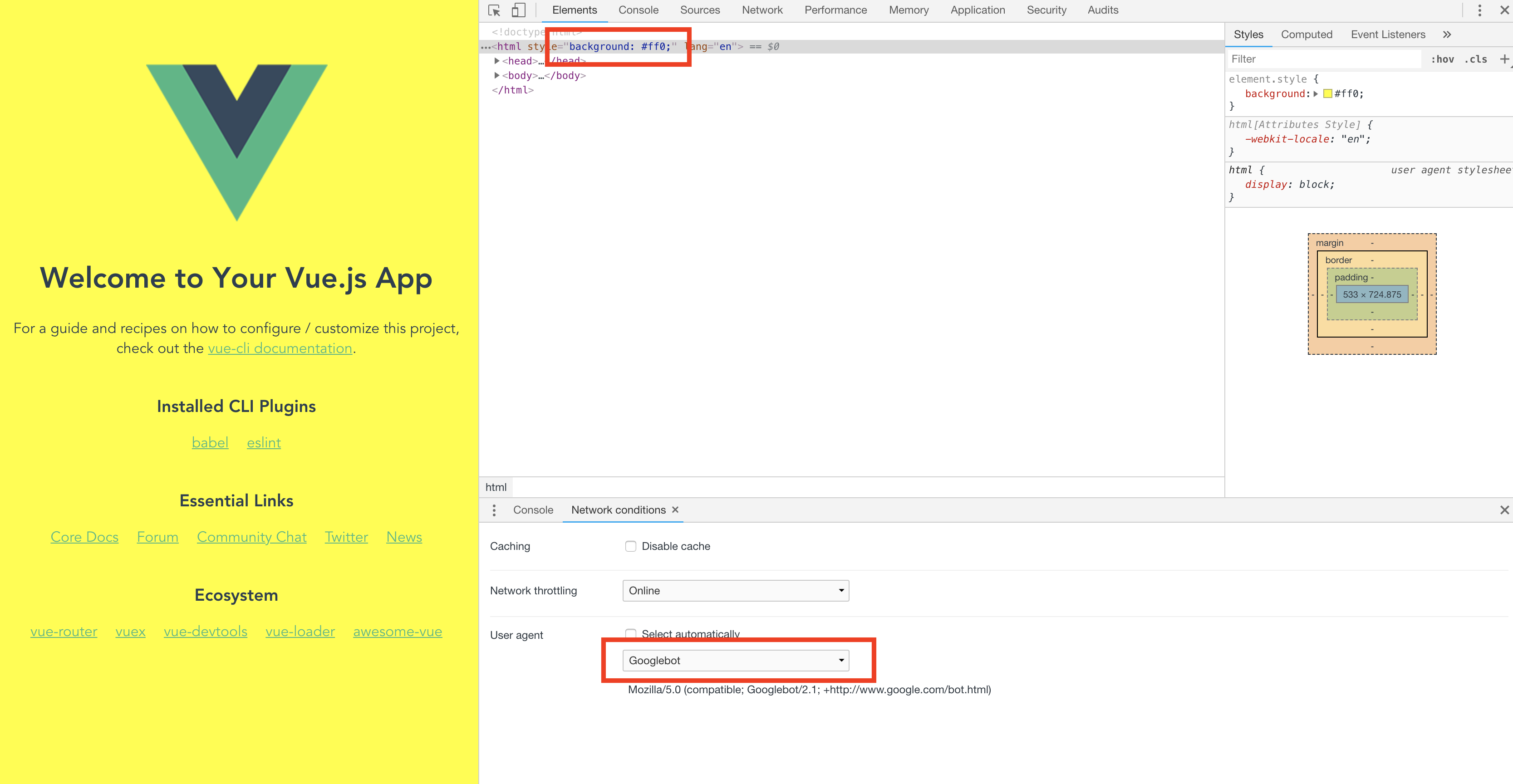
動作確認は、Chrome の DevTools のNetwork conditionsからGooglebotをチェックしてサイトにアクセスすることで確認出来る。
ボットの時に黄色のページが表示されて、ボットじゃない時は元のページが表示されれば OK。
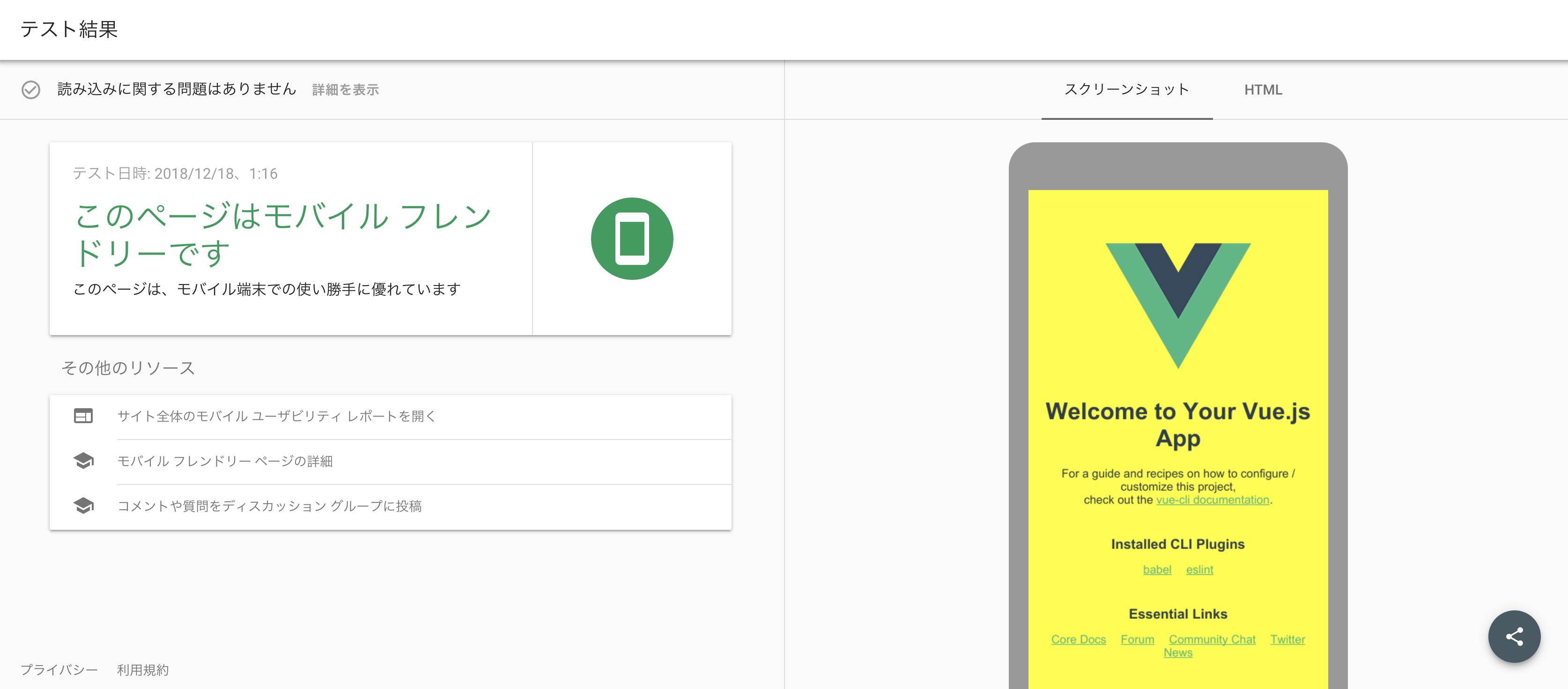
モバイルフレンドリーテストも OK
Fetch as Googleも問題なさそう。

まとめ
Lambda + Puppeteer でダイナミックレンダリングが出来た。
Lambda の仕組みからよく分かってなかったのでキャッチアップしながら進めて、内容的にもそこまで難しくもないだろうと思っていたが、Lambda の 50MB の制限やメモリを上げないといけなかった事とかハマるポイントはあった。
実際はLambdaでPuppeteerを動すが出来たらあとは html 取得して返すだけなので、動かすところまでがキモになりそう。
おしまい。